Base64 是网络上最常见的用于传输 8Bit 字节码的编码方式之一,Base64 就是一种基于64个可打印字符来表示二进制数据的方法。
Base64编码由以下64个字符构成: ‘A-Z’(26),‘a-z’(26),‘0-9’(10),’+’(1),’/’(1)
¶原理
以 Hello,World! 共12个字符为例,需要经过以下几个步骤完成编码过程:
-
将原文字符每3个字节一组进行划分
划分为Hello,World!这四个部分 -
将每组3个字节转化为24位二进制
1
2
3
4Hel 010010000110010101101100
lo, 011011000110111100101100
Wor 010101110110111101110010
ld! 011011000110010000100001 -
将24位二进制数按6位一组转化成4个十进制数
之所以按6位一组,是因为6个二进制位正好表示0~63,对应 Base64 字符表的64个字符1
2
3
4Hel [18, 6, 21, 44]
lo, [27, 6, 60, 44]
Wor [21, 54, 61, 50]
ld! [27, 6, 16, 33] -
将十进制数按 Base64 字符表编号查找相应字符
1
2
3
4Hel SGVs
lo, bG8s
Wor V29y
ld! bGQh -
将每组字符按原先字符组成顺序连接为原字符的 Base64 编码
Hello,World!的 Base64 编码为SGVsbG8sV29ybGQh
总的操作过程是:将所有的字符转换为二进制,然后每6个二进制位一组,不足6位的低位补充0,每6个二进制位转换为对应的十进制数查ascii表得到对应的ascii。
¶代码实现
根据基本原理,使用 Python 代码实现基础功能。
1 | def base(string:str)->str: |
¶代码解释
进制转换内置函数只能是数字作为对象,或者其他进制表示的数字
bin()用于将各进制数转换为二进制表示,开头以0b表示,如0b1001000oct()用于将各进制数转换为八进制表示,开头以0o表示,如0o110hex()用于将各进制数转换为十六进制表示,开头以0x表示,如0x48int()用于将各进制数转换为十进制表示,如72
int(x, base=10) 可以接受各进制数,以及字符串形式的数字转换为对应的整型
1 | 将二进制'0b1001000'转换为对应的十进制表示 |
ord()用于获得字符对应的ASCII码,chr()相反,用于获得ASCII码对应的字符。
所以要获得字符的二进制码,需要使用先使用ord()函数得到字符对应的ascii码,然后使用bin()得到对应的二进制。
如果最后剩下两个输入数据,在编码结果后加1个“=”;如果最后剩下一个输入数据,编码结果后加2个“=”;如果没有剩下任何数据,就什么都不要加,这样才可以保证资料还原的正确性。
注意:以上代码只是原理的简单实现,只适用于ASCII的码,不能用于汉字
¶Python内置模块
Python 内置的 base64模块 可以直接进行base64的编解码。
1 | import base64 |
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_
1 | import base64 |
¶编码与转码
常用编码说明:
ASCII码:只有一个字节,且开始的时候连最高位都没有用,为0,只用了后7位,共127个来存储英文。
GB2312:为了能使用两个字节表示一个汉字,所以使用两个字节来存储一个字符。
Unicode:是编码标准,规定了使用两个字节来表示一个字符,足以涵盖世界上所有的语言,是计算机内数据存储的编码方式。
UTF-8:诞生是因为Unicode编码标准规定所有的都是用两个字节,但是英文只要一个字节存储足矣,所以为了节省空间,提出了utf-8, 是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号(用一个字节表示英文,三个字节表示汉字),根据不同的符号改变字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间,这也是为什么utf8是我们的推荐编码方式。
Unicode与utf8的关系:
一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
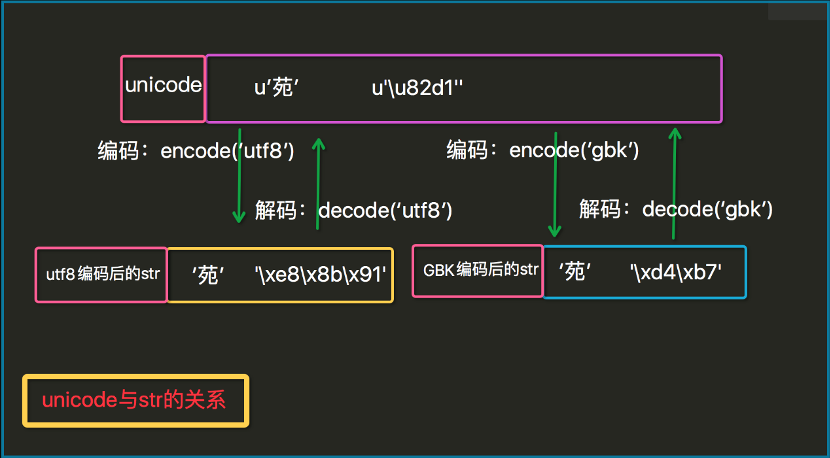
解释:
可见在计算机内部的编码是unicode标准存储的,即一个字符两个字节。
通过 encode 使用utf-8编码后,一个汉字占3个字节
通过 encode 使用gbk编码后,一个汉字占2个字节
想要获得unicode,需要使用对应的编码 decode 进行还原。
所以不同的编码规则之间是不可以直接进行转换的,否则会因为存储字节数的不同(有的即使字节数一样,使用的编码表也是不同的),导致乱码,即使不是乱码,也和原本要存储的不一致。所以若要将utf-8的数据要变成gbk类型的数据,需要先 decode(utf-8) 还原成unicode标准,然后再 encode(gbk) 变成gbk类型。
¶Python3 编码处理
Python3中字符串就是unicode编码,而计算机内存中处理的时候也是使用的unicode编码。
这里需要明确一点就是:计算机在内存中处理信息时使用的是unicode编码,但是存储的时候会转换成某种编码方式编码的bytes字节串进行存储,不同的系统、不同的软件使用的编码格式可能不同,
因为utf-8为可变长编码,占用的空间要少于unicode,所以在网络传输,硬盘存储的时候都是将unicode编码变成utf-8编码在去处理,主要是英文只占了一个字节,而英文是网络传输和存储中被大量使用的字符。
如果一个我们读取一个文件,改文件保存时的编码是比如gbk,则我们在读取的时候,就应该先 encoding = ‘gbk’ (只用encoding,此时的encoding和encode()不是同一个意思,encode指定的进行编码这个动作的格式,而encoding是指定文本的使用的编码方式) 或是 文本.decode(“gbk”) 解码为unicode在进行操作。
再如网络传输的时候,都要先使用str.encode(“utf-8”) 将unicode转变为utf-8编码进行传输,在接受到数据的时候再使用 数据.decode(“utf-8”) 将str解码为 unicode处理
Python3中str类型存unicode数据(两个字节),bytse类型存bytes数据(字节型)
通过在字符串之前使用 b’字符串’ 的方式,可以声明字节类型,但是这种方式后面的字符串只能是ASCII码,此外可以使用 bytes(‘字符串’,encoding = ‘编码方式’) 得到相应编码的二进制数据。
使用 str(‘二进制编码’, encoding = “解码方式”) 可以还原到原始的str类型数据(使用的unicode两个字节存储的)
1 | name = '小明' |
这是一对互逆操作。
Python3的解释器的默认解码方式是utf-8,而Python2的解释器使用的默认解码方式是ascii,所以要在开头声明 #coding:utf8,用于指定python2解释器读取python文件使用的解码方式(此时需要python文件的编码格式是utf8,否则需换成相应的格式,如 #coding:gbk, 但是目前使用的都是utf8)。
这里要注意区分,Python3的解释器的默认解码方式是utf-8,指的是以utf-8去解释Python文件,读取其中的内容,所以Python文件在创建的时候使用utf-8编码(一般应用创建的文件多数都采用的utf-8编码,磁盘存取时会自动完成utf-8和unicode的转换)。
而Python3中str类型存unicode数据,是指在内存的操作(通过 .encode('unicode_escape') 的编码方式,发现是使用的2个字节的unicode存储方式),两者不是一个层面的意思。
在Python3中定义str类型,既可以使用直接的表述(a =’你好’),也可以使用它对应的unicode编码,因为str在内存中以unicode表示。a = b'\xe4\xbd\xa0\xe5\xa5\xbd' 两者是等价的,因为本质上都是同一个二进制数据的不同的表现形式,一个是string类型,一个是它使用utf-8编码格式对应的字节类型。
所以说unicode表示的内容是不变的,然后通过 .encode(编码格式) 编码得到相应编码格式的二进制字节型数据,因为各种编码格式不同(占用的字节不同),所以编码后续使用原来的编码格式进行解码才能得到源数据,不能混用,会出现乱码。
所以说:当我们有需求说要将一个str装换为字节型数据的时候,实际就只要 encod("一种编码格式") ,由于使用的编码格式不同,我们转换的字节型数据就有多种,这是没有问题的,而我们之所以会一般选择utf-8来进行编码,因为占用的资源较少
1 | ''' |
文本文件,都是使用unicode存在内存中的,当涉及到音频、视频、图像文件的时候,都是二进制流,所以open操作这些类型的文件的时候要加b。
¶乱码问题
创建一个urf-8编码的文件test.txt,内容是hello,王小明,使用下面的程序,分别在win和非win系统下运行:
1 | with open('./test.txt') as f: |
在win系统下,打印的内容为:hello锛岀帇灏忔槑
在非win系统下,打印的内容为:hello,王小明, 可以正常打印。
这是因为你的win的操作系统安装时是默认的gbk编码,而linux操作系统默认的是utf8编码。当执行open函数时,调用的是操作系统打开文件,操作系统用默认的gbk编码去解码utf8的文件,自然乱码,此时只要添加encoding='utf-8'参数,指定使用的编码方式为utf8即可。如果你的文件保存的是gbk编码,在win 下就不用指定encoding了。另外,如果你的win上不需要指定给操作系统encoding=‘utf8’,那就是你安装时就是默认的utf8编码或者已经通过命令修改成了utf8编码。
所以,为了代码的兼容性,推荐还是需要设置 encoding 参数的。
编码的本质: 使用不同的字符表获得相应的字符,底层存数据的时候都是二进制,只是各种编码方式的字节不同,也就是断句不同,所以要以相应的编码处理。
¶总结
Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
除了使用标准的 Base64 字母表,还可以自己定义64个字符的排列顺序,这样就可以自定义 Base64 编码,不过,通常情况下完全没有必要。
Base64 是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64 适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
Base64是一种任意二进制到文本字符串的编码方法,常用于在 URL、Cookie、网页中传输少量二进制数据。
参考:官方文档:https://docs.python.org/zh-cn/3/library/base64.html
廖雪峰:https://www.liaoxuefeng.com/wiki/897692888725344/949441536192576
python编码:https://www.cnblogs.com/yuanchenqi/articles/5956943.html